Today we talk about multimodal recommendations. We will review a latest paper from Liu et al., CIKM 2024, titled “AlignRec: Aligning and Training in Multimodal Recommendations”. You can find the paper here https://arxiv.org/pdf/2403.12384 at the end, but we will fill you in with the necessary backgrounds first. If you know well, please skip this part.
Background
Online recommendations are crucial in today’s digital landscape as they personalize the user experience, drive engagement, and enhance customer satisfaction. By analyzing user behavior and preferences, recommendation systems suggest relevant products, content, or services, leading to increased conversions and loyalty. For instance, platforms like Amazon use collaborative filtering to suggest products based on similar users’ purchases, while Netflix employs content-based filtering to recommend shows aligned with individual viewing histories. Key techniques include collaborative filtering, content-based filtering, and hybrid methods, which combine multiple algorithms to improve accuracy and relevance, making online experiences more intuitive and tailored.
With the progress of deep learning, recommendation techniques has developed into the next stage of using deep neural networks trained to encode users and items in many different ways. However, multimodal recommendations has emerged as a new domain because the availability of large multimodal language models (LLM) such as CLIP and LLAVA. Those models encode users as embeddings and items as embeddings and assume users are similar to the items that they may be interested in. Mathematically this is achieved by something called vector dot product / cosine similarity that mathematically says if two embeddings are similar.
The core of the success lies in the training technique that obtains those embeddings.
First wave of embedding innovation was in the early 2010s. Some static embeddings such as word2vec[] and GloVe[] was trained on texts and never adjusted later. They are trained on smaller datasets such as books data or wikipedia.
Second wave was in mid 2010s. It is a short period where people embeds word2vec and GloVe into more complex models with attention mechanism and train the models end to end. This method leads to some improvements. One catalyst is the Stanford Question Answering Dataset (SQuaD) where the task is to find an answer to a question in a given Paragraph. This task ignited the excitement of creating Deep learning models that trains on the provided dataset. However, soon people found word2vec and GloVe to be inadequate.
Since the late 2010s, i.e. 2017, with the invention of Transformers, people have found that pertaining a model with more data, and then fine-tune on a smaller, task-specific dataset achieves better results. This pretrain-and-finetune idea has refreshed a lot of the state-of-the-art on language, vision tasks.
Since the 2020, there are a couple of models that are ‘industry standard’ methods. For example, the CLIP model that are fine-tuned to align texts and vision, the BERT model and its variants that are pre-trained on different datasets with slightly different but very similar objectives, …
Those models create something called ’embedding’, which converts the inputs to a numerical vector representation. Using vanilla BERT or variants, the embedding training was usually successful for classification tasks, say, if a review is positive or negative. But, when you want to tell which review is similar to which, especially when there are a lot of reviews to compare, such model will be confused because they are not trained for the task to be aware of the differences.
in 2020, A task called Contrastive representation learning stands out to solve the problem. The idea is, the training objective should align with such embedding comparison, and we should make a great deal of comparisons during training. From (Radford et al., 2021) about the CLIP model:
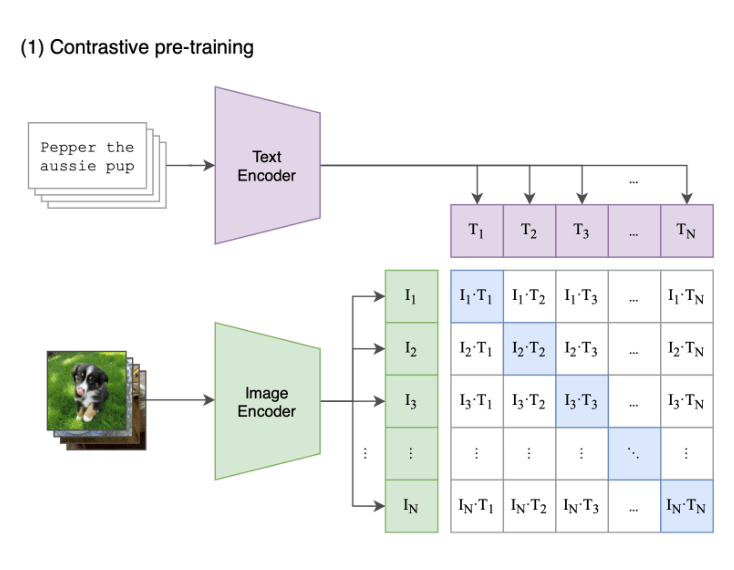
As is shown in the image above, a piece of text T_i will compare to N images in the same batch, and usually N is at the scale of 1E5, which is A LOT! Imagine that we use models such as BERT as the encoder for text. IT IS A LOT OF MEMORY. That’s also why people tend to use CLIP models out of the box most of the time, and do not fine tune it much.
OK, why is this important? This paper gives an answer:
Wang, Tongzhou, and Phillip Isola. “Understanding contrastive representation learning through alignment and uniformity on the hypersphere.” International conference on machine learning. PMLR, 2020.
In plain words, training with contrastive loss can encourage the nice properties in the embedding space, and the embeddings are put in nice positions in this space that spreads out nicely, but close to each other when necessary.
This is one of the most important reason for the success for the paper we are about to review.
Liu et al., CIKM 2024
This paper focuses on multi-modal recommendations, where user or item representation can be multi-modal. The key point of the paper is:
When you use two modalities as input to produce a single representation, you need to make sure both text and image should lie in the same embedding space. When they do, the model could better leverage both embeddings.
When they are not, then the model has to make a great effort to align the two spaces.
The (d) in the Figure below illustrates the paper’s core idea.
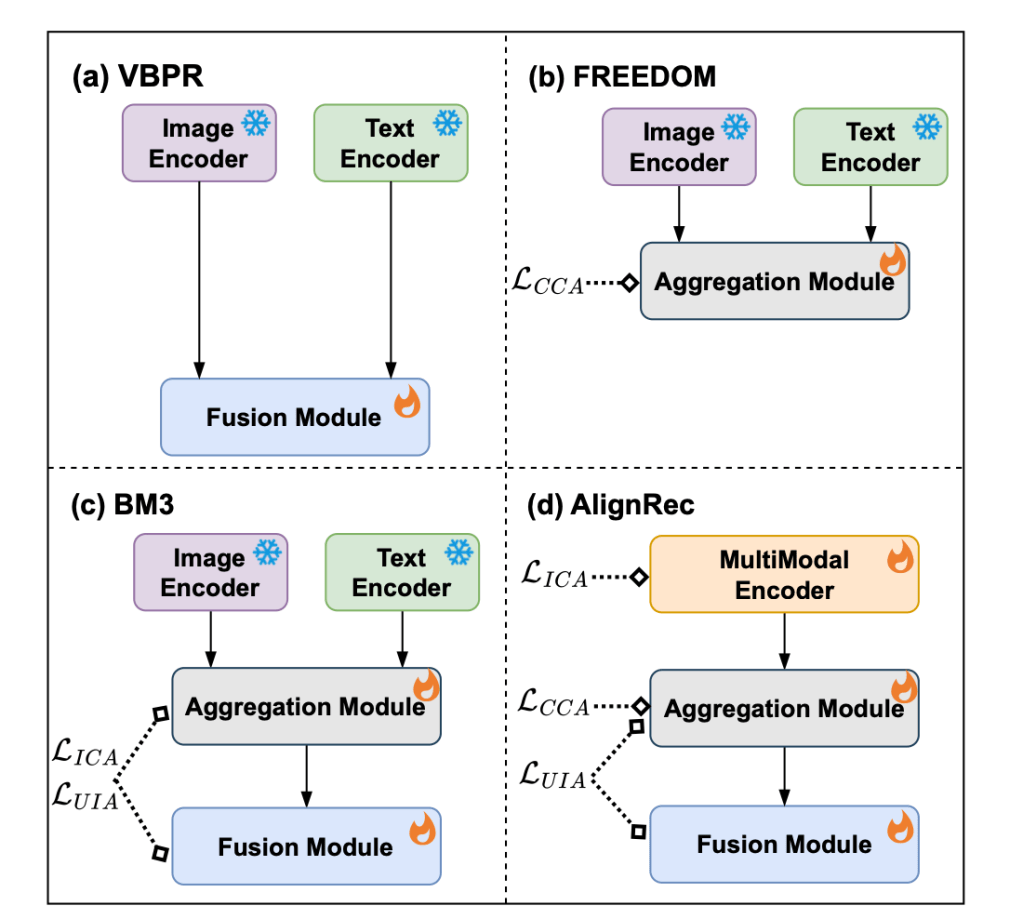
And within an item representation, say, title and image, the representation of the title and image should be with the same model. And then, there is a pre-training routine that aligns the title and image embeddings. They defined three alignment objectives shown below
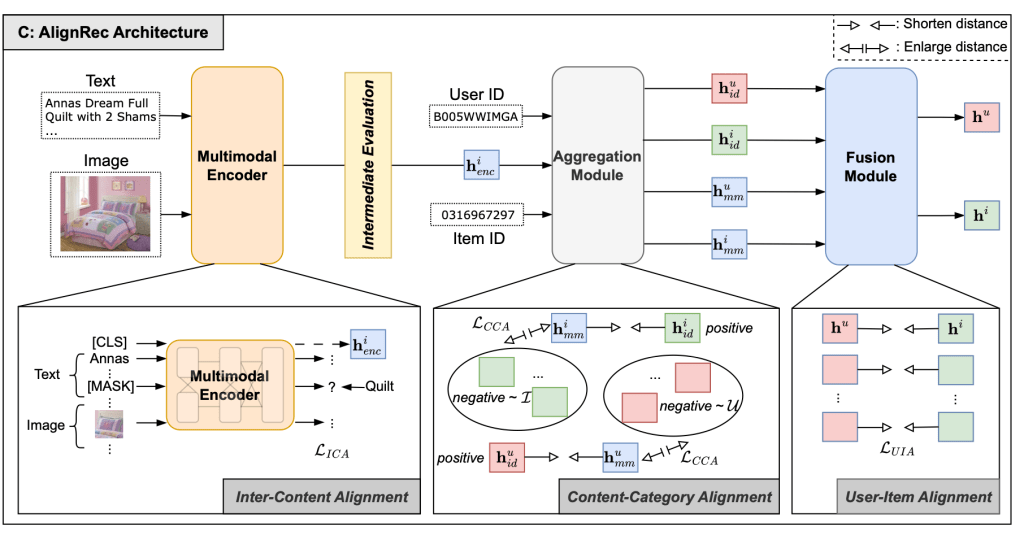
Table 2. shows that AlignRec performance compared to previous approaches on three Amazon Recommendations datasets. AlignRec significantly improvements over the SOTA, by 10% in general.
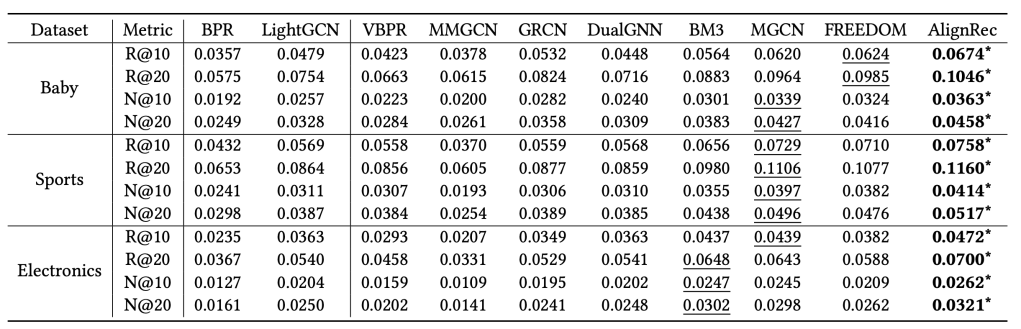
However, if we look at the Recall@K and NDCG@K metrics, the absolute values are still pretty low in general.
One of the promise of embedding approach for recommendations is the ability to deal with the cold-start problem naturally. i.e. if there is no interaction for a new user or a new item, we can leverage embedding space’s ability to measure similarity between a new user to existing items.
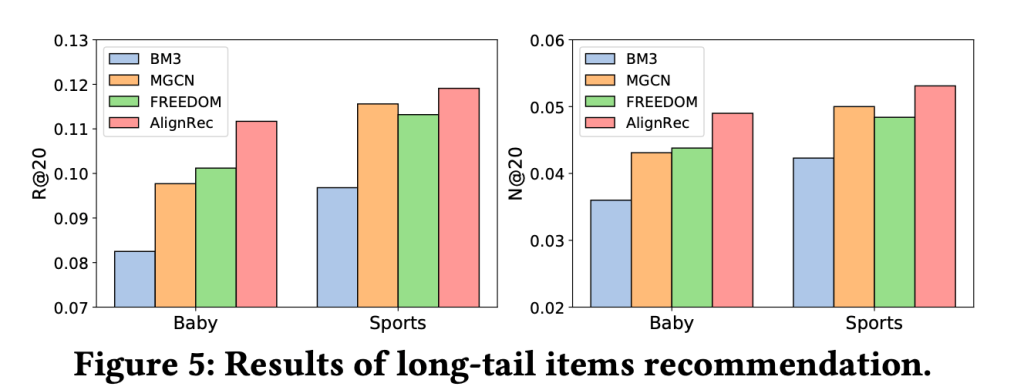
In Figure 5, authors show that the AlignRec performs well on long-tail items recommendation. I am not sure if there is an experiment on a new user though.
Efficiency:
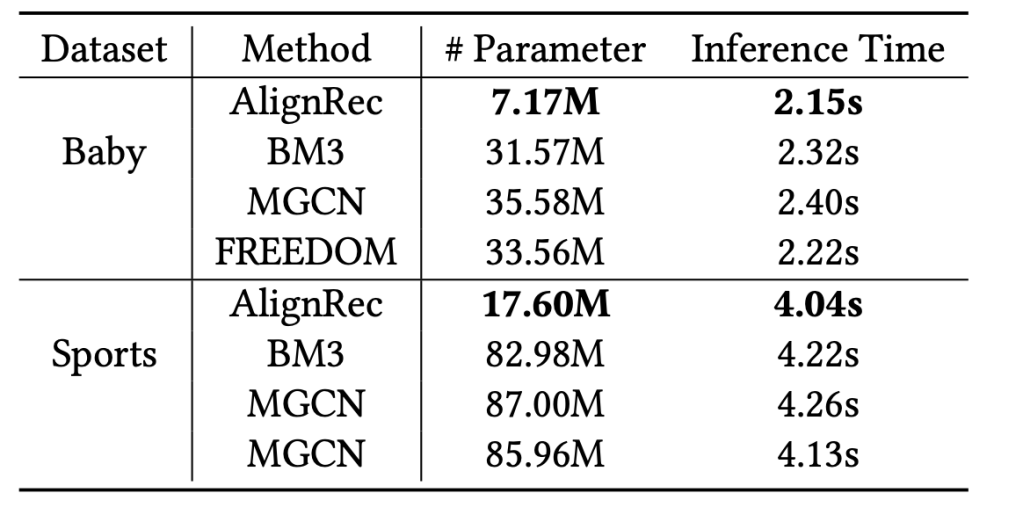
The inference time suggests that the model can be used as an offline recommendations engine for e.g. marketing efforts, instead of the real-time online inference.
References
[]CLIP embedding
[]word2vec embedding
[]GloVe embedding
[]Squad dataset
[] Liu, Yifan, Kangning Zhang, Xiangyuan Ren, Yanhua Huang, Jiarui Jin, Yingjie Qin, Ruilong Su, Ruiwen Xu, and Weinan Zhang. “An Aligning and Training Framework for Multimodal Recommendations.” arXiv preprint arXiv:2403.12384 (2024).

Leave a comment